
Cuando empiezas a construir agentes de inteligencia artificial que trabajan con documentos, conocimiento interno o grandes volúmenes de información, aparece una duda clave:
¿conviene usar una base de datos vectorial o simplemente subir documentos directamente a la OpenAI Platform en PDF o Word?
La respuesta corta es: depende del objetivo, pero la respuesta profesional es que no rinden igual ni están pensadas para el mismo escenario.
En este artículo te explico primero cómo funciona un flujo típico de bases de datos vectoriales, luego lo comparo con la subida directa de documentos a OpenAI, y finalmente te doy una recomendación clara de arquitectura para agentes de IA.
Cómo funciona un flujo con base de datos vectorial (paso a paso)
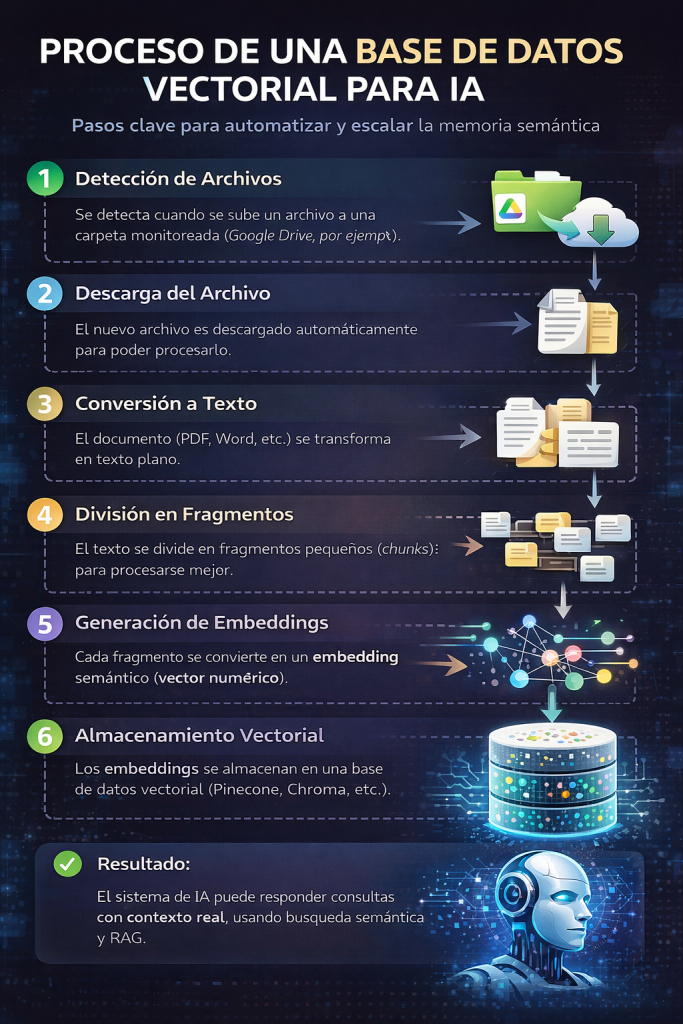
El flujo que describes es un ejemplo clásico y correcto de arquitectura RAG (Retrieval Augmented Generation) automatizada. Veamos qué hace realmente cada paso y por qué existe.
Detección automática de archivos en Google Drive
El proceso comienza con un trigger de Google Drive que detecta cuando se crea o se sube un nuevo archivo en una carpeta específica.
Esto permite que el sistema:
- Funcione de forma automática
- No dependa de acciones manuales
- Escale a múltiples documentos sin fricción
Cada nuevo archivo activa el flujo completo.
Descarga del archivo
Una vez detectado el archivo, el sistema lo descarga automáticamente desde Google Drive para poder procesarlo.
Este paso es clave porque los modelos no trabajan directamente con archivos “en bruto”, sino con texto.
Conversión del documento a texto
El Data Loader toma el archivo descargado (PDF, Word, etc.) y lo convierte en texto plano.
Aquí pueden intervenir:
- Parsers de PDF
- Lectores de Word
- OCR si el documento es escaneado
El resultado es un documento completamente legible por el sistema de IA.
División del texto en fragmentos (chunking)
El Token Splitter divide el texto en fragmentos más pequeños llamados chunks.
Este paso existe por dos razones fundamentales:
- Los modelos tienen límites de tokens
- Fragmentos más pequeños preservan mejor la coherencia semántica
Un buen chunking evita que el contenido se corte mal o se pierda contexto importante.
Generación de embeddings con OpenAI
Cada fragmento de texto se convierte en un embedding, es decir, un vector numérico que representa su significado semántico.
Aquí ocurre algo clave:
el texto deja de ser texto y pasa a ser matemática semántica.
Esto permite que el sistema:
- Compare significados, no palabras exactas
- Encuentre información relevante aunque la pregunta no coincida literalmente
Almacenamiento en una base de datos vectorial (Pinecone)
Los embeddings se almacenan en Pinecone, una base de datos diseñada específicamente para búsqueda por similitud semántica.
Gracias a esto:
- Las búsquedas son extremadamente rápidas (milisegundos)
- El sistema escala a miles o millones de documentos
- El conocimiento queda persistente y reutilizable
A partir de aquí, el agente de IA ya tiene una base de conocimiento viva.
Resultado final del flujo vectorial
Cada nuevo documento:
- Se indexa automáticamente
- Se vuelve consultable
- Enriquece la memoria del sistema
Este enfoque es la base de los asistentes de IA profesionales que responden con contexto real y actualizado.
Qué pasa cuando subes directamente un PDF o Word a OpenAI Platform
El segundo enfoque es mucho más simple: subir un archivo directamente a la OpenAI Platform y hacer preguntas sobre él.
En este caso:
- OpenAI gestiona el contexto
- El modelo analiza el documento completo
- Puedes interactuar sin crear infraestructura adicional
Este método es útil, pero tiene limitaciones claras.
Diferencias reales de rendimiento entre ambos enfoques
Rendimiento y velocidad
Con una base de datos vectorial:
- La búsqueda es extremadamente rápida
- Solo se envía al modelo el contenido relevante
Con subida directa:
- El modelo procesa documentos grandes completos
- El rendimiento depende del tamaño del archivo
Escalabilidad
Las bases de datos vectoriales:
- Escalan a miles o millones de documentos
- Mantienen rendimiento estable
La subida directa:
- Funciona bien con pocos documentos
- Se degrada rápidamente a gran escala
Uso de tokens y costos
Vector DB:
- Usas tokens solo en la respuesta
- Coste bajo por consulta
Subida directa:
- Alto consumo de tokens
- Coste elevado si se consulta con frecuencia
Persistencia del conocimiento
Vector DB:
- El conocimiento queda indexado
- Se reutiliza infinitas veces
Subida directa:
- El documento se vuelve a procesar
- No hay indexación semántica persistente
Cuándo usar cada enfoque
Usa bases de datos vectoriales + RAG si:
- Construyes agentes de IA
- Trabajas con muchos documentos
- Necesitas escalabilidad
- Buscas eficiencia de costos
- Quieres respuestas precisas y repetibles
Usa subida directa de documentos si:
- Estás prototipando
- Analizas documentos individuales
- Haces pruebas rápidas
- No necesitas memoria a largo plazo
Recomendación profesional
Para proyectos serios, productos, asistentes para clientes o sistemas de conocimiento, la base de datos vectorial no es opcional, es estructural.
La subida directa de documentos es útil como atajo inicial, pero no es una arquitectura sostenible cuando el sistema crece.
Si tu objetivo es crear agentes de IA robustos, escalables y rentables, el camino correcto es:
embeddings + base de datos vectorial + RAG.
Llamado a la acción
Si quieres aprender a diseñar este tipo de arquitecturas, elegir la base vectorial correcta y crear agentes de IA listos para producción, visita ottoduarte.com y accede a mis formaciones prácticas.
Nota de transparencia
Este contenido ha sido generado o asistido por herramientas de Inteligencia Artificial, bajo la supervisión de EL PROFE OTTO.